The SaaS playbook has changed. Chasing user growth at any expense is no longer viable. Instead, data ownership now determines success and valuation. Companies controlling proprietary data are commanding 8x–12x EBITDA multiples, while those relying on third-party APIs see just 3x–5x. This shift is driven by AI's ability to disrupt traditional workflows, exposing weaknesses in unsustainable growth models.
Key takeaways:
- AI disruption: Rising AI adoption has made commoditized products obsolete, favoring businesses with exclusive datasets.
- Investor priorities: Valuations now focus on gross profit and proprietary data, not just ARR growth.
- SaaSpocalypse: $285 billion in software market cap vanished in early 2026, showcasing the risks of outdated strategies.
- Data flywheels: Companies building systems that improve with user interactions gain a lasting edge.
To succeed, founders must focus on owning data, creating AI-driven pipelines, and designing systems that continuously improve. Data is no longer just an asset - it’s the moat defining winners in 2026 and beyond.
Understanding SaaS Valuations: How to Navigate the 3x to 10x ARR Range | SaaS Metrics School
sbb-itb-9cd970b
Why 'Growth at All Costs' No Longer Works
The playbook that worked between 2016 and 2021 has fallen apart. During the era of zero-interest rates, founders had access to cheap capital, which they poured into aggressive user acquisition strategies. The idea was that unit economics would eventually improve at scale. But that assumption no longer holds true. In 2023, global VC investment dropped by 35% year-over-year, and median SaaS acquisition costs hit $2.00 for every $1.00 of new ARR. Clearly, the math no longer works [7]. This shift is pushing founders to adopt spending strategies that prioritize sustainability over unchecked growth.
The Real Costs of Unchecked Growth
The numbers paint a stark picture. Customer acquisition costs (CAC) have surged by 222% since 2013, with an additional 40–60% increase between 2023 and 2025 alone [7]. On average, brands are now losing $29 for every new customer they acquire [7]. These rising costs are largely due to platform dependency and privacy policy changes. For example, when Apple introduced iOS 14.5, companies heavily reliant on platforms like Meta and Google saw their customer acquisition pipelines collapse almost overnight.
"The growth-at-all-costs model did not just become unfashionable. It became mathematically untenable." - Mixo Ads [7]
Chegg’s downfall is a prime example of how growth can mask product flaws. Startup failures hit an all-time high in 2024, with 277 companies shutting down - a 29% increase from the previous year [7]. Meanwhile, down rounds, once a rarity, made up 20% of VC deals in 2023, up from just 8% in 2022 [7].
AI has also disrupted the economics that once made SaaS so appealing. Traditional SaaS companies thrived on gross margins of 70–80%, but AI-native companies now face inference costs that have slashed margins to 50–65% [2][3].
"For the first time in SaaS history, the marginal cost of adding a user is not close to zero." - Amanda Huang, Bain Capital Ventures [3]
Market Shifts Toward Efficiency and Profitability
Given these cost pressures, investors have completely redefined how they value software companies. Public SaaS valuations have plummeted by 65–75% from their 2021 highs, with median EV/Revenue multiples dropping from 18–21x to just 5–7x by early 2026 [3]. The market is no longer rewarding rapid top-line growth; instead, it penalizes companies that fail to show operational efficiency and profitability.
The "Rule of 40", which combines a company’s growth rate and profit margin, highlights this shift. Only 17% of public SaaS companies meet this benchmark today, compared to 35% in 2022 [2]. Investors have also shifted their focus from ARR multiples to Gross Profit multiples, given the variability of AI infrastructure costs. For example, a company generating $20 million in ARR with a 78% margin produces 35% more gross profit than one with $20 million in ARR and a 58% margin. Valuing both companies based solely on revenue would completely overlook this economic disparity [2].
The February 2026 market correction, nicknamed the "SaaSpocalypse" by Wall Street, wiped out over $1 trillion in software market capitalization [3][8]. Companies burning through cash to chase user growth saw their valuations collapse. As the blitzscaling era ends, the focus has shifted to building businesses that are data-driven and sustainable. Companies with proprietary data now hold a distinct advantage and are likely to command premium valuations in this new landscape.
Data Ownership Now Determines Exit Multiples
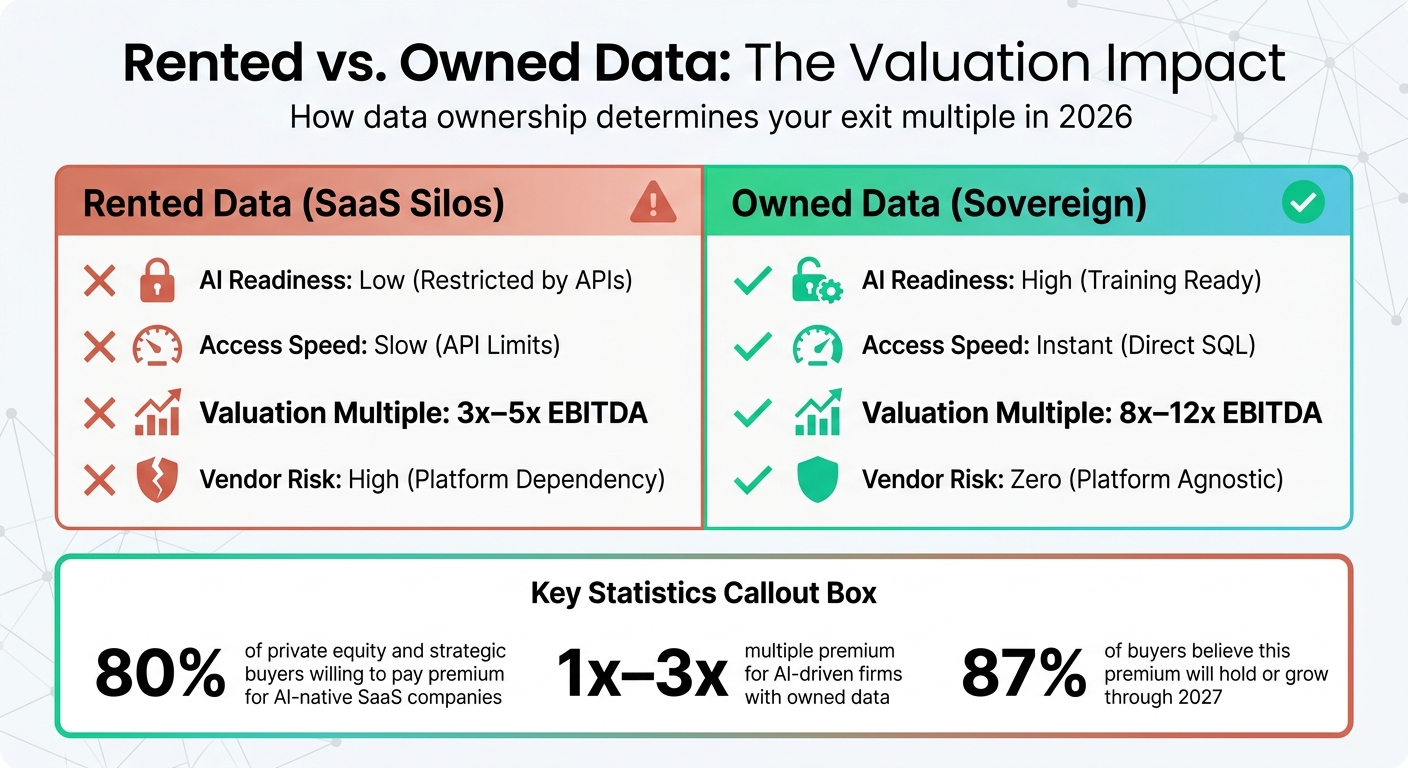
Rented vs Owned Data: Impact on SaaS Valuation Multiples
Today’s investors are looking beyond just ARR growth. They’re prioritizing proprietary data - the kind that competitors can’t duplicate. Companies with exclusive data assets are commanding 8x–12x EBITDA multiples, compared to just 3x–5x for those relying on third-party platforms [6]. In fact, 80% of private equity and strategic buyers are willing to pay a premium specifically for AI-native SaaS companies [4]. For these AI-driven firms, owning data often translates into a 1x–3x multiple premium over their non-AI counterparts [4]. What’s even more striking? 87% of buyers believe this premium will hold or even grow through 2027 [4]. It’s clear: proprietary data has become the cornerstone of valuation.
"AI cannot fabricate real-time liquidity, courier density, reputation history, or a canonical identity graph. Marketplace density and trust are structural, not labor-based." - Tanay Jaipuria, Partner, Wing VC [12]
This shift is happening because AI models themselves are becoming more accessible - whether open-source or rentable. What sets companies apart isn’t the AI machinery but the data feeding it. Proprietary data acts as the catalyst that elevates AI performance, making it a critical factor in both product success and market valuation [9][11]. And when AI is combined with these exclusive data assets, the competitive advantage becomes even stronger, as we’ll explore further.
How Data Increases Company Value
Proprietary data doesn’t just boost valuation multiples - it creates lasting advantages. It does this in three key ways: defensibility, compounding returns, and cognitive lock-in. Unlike code, which is easy to replicate, historical data grows more valuable with time. For instance, a company with a decade’s worth of industrial sensor data has built an asset that competitors simply can’t recreate [10].
Take Epic Systems as an example. By linking longitudinal health records for one-third of Americans, the company has created a structural advantage in the U.S. Electronic Health Record market. Its "Cosmos" database powers predictive AI tools that rivals can’t match without decades of similar data [5][10]. This isn’t just a technical edge - it’s a moat that directly translates into higher valuation multiples.
NielsenIQ offers another case in point. With 40 years of retail scanner data built through long-term agreements, it’s become indispensable to CPG brand managers. This dataset has essentially become the “operating system” for the industry, making it nearly impossible for competitors to replace [10]. When data becomes integral to decision-making, switching costs skyrocket.
The numbers back this up. Companies with Net Revenue Retention (NRR) above 120% trade at 1.4–1.8x the valuation multiples of those with NRR between 100–110% [2]. Why? Data-driven personalization and predictive features directly improve retention, which in turn drives higher multiples.
"If the base model improves 10x next year, does my product get more valuable or less? Less valuable means you are a wrapper. More valuable means a smarter model does more with your data." - Lewis C. Lin, Software Strategist [10]
How AI Tools Enhance Data Analysis
Proprietary data becomes even more powerful when paired with AI tools. These tools transform raw data into actionable insights, creating a strategic edge. But here’s the catch: this advantage only exists if you control the underlying data. The industry’s shift from ARR multiples to Gross Profit multiples reflects this reality. Investors now factor in cost structures because AI inference costs can vary significantly - gross margins for AI-native SaaS companies range from 52% to 85%, depending on their data architecture [2].
The difference between owning data and "renting" it from SaaS platforms is stark:
| Metric | Rented Data (SaaS Silos) | Owned Data (Sovereign) |
|---|---|---|
| AI Readiness | Low (Restricted by APIs) | High (Training Ready) |
| Access Speed | Slow (API Limits) | Instant (Direct SQL) |
| Valuation Multiple | Low for rented data | High for owned data |
| Vendor Risk | High (Platform Dependency) | Zero (Platform Agnostic) |
Source: [6]
The real game-changer? Feedback loops. Companies that design products to continuously improve their datasets - through user clicks, corrections, or interactions - create a compounding advantage that rivals can’t replicate [5][13]. This transforms data into a dynamic, self-improving asset.
"The multiple moves when AI shows up in your retention and expansion numbers - not when it shows up in your product roadmap slides." - Khaled Azar, Livmo [4]
A real-world example is The Free Press. In October 2025, the media company was acquired for $150 million. The premium price reflected its "owned distribution" - a direct subscriber base - rather than mere web traffic [12].
Currently, only 6% of companies achieve meaningful EBIT impact from AI [4]. The difference between "AI theater" and actual AI value boils down to data ownership. Companies that own their data can refine AI models, improve personalization, and predict market trends - all of which drive higher valuation multiples. By integrating AI with proprietary data, businesses not only solidify their market position but significantly boost their exit valuations.
Case Study: Data-Focused Strategies for SaaS Exits
Many companies are shifting their focus from chasing growth at all costs to adopting strategies rooted in measurable, data-driven results. AgileGrowthLabs exemplifies this shift. They transitioned from traditional growth marketing to their "Growth & Exit Engine™" - a system that combines AI-driven revenue operations with merger and acquisition (M&A) strategies [15]. Their expertise, drawn from experience in $43 billion in mergers and 70-company roll-ups [15], underscores how controlling critical data can directly impact revenue and valuation.
A key element of their approach is the Valuation Health Score™, a diagnostic tool designed to identify which key metrics - such as pipeline performance, pricing models, churn rates, and profit margins - affect a company’s valuation over a 12–24 month period [15]. Rather than focusing on vanity metrics, this system ensures that internal data aligns with the metrics investors prioritize. It’s not about gathering more data; it’s about owning and structuring the right data to craft a compelling narrative for potential buyers.
Using AI Analytics for Lead Generation
Take MarketEdge as an example. This SaaS company was struggling with stagnant growth, stuck at $40,000 in monthly recurring revenue (MRR) and dealing with inconsistent lead flow. After implementing AgileGrowthLabs’ AI-powered go-to-market (GTM) and revenue operations (RevOps) systems, MarketEdge saw its MRR jump to $65,000 in just 90 days - a 62.5% increase [15].
"Before joining the Growth Accelerator, our MRR was stuck at $40K, and we struggled with inconsistent leads. Within 90 days, we scaled to $65K MRR, a 62.5% increase." - Jamie L, Founder at MarketEdge [15]
This dramatic growth wasn’t due to higher ad spending or additional hires. Instead, AI tools were used to analyze customer behavior, detect high-intent signals, and automate the lead qualification process. By leveraging behavioral data, MarketEdge turned guesswork into a repeatable, predictable lead-generation system. Beyond boosting revenue, this approach enhanced the company’s valuation by demonstrating that its growth engine was systematic and not reliant on the founder’s personal efforts.
Creating Competitive Advantages with Proprietary Data
Social Link offers another example of how data can transform a business. Initially, the company faced operational inefficiencies and lacked focus - symptoms of prioritizing growth over sustainability. AgileGrowthLabs helped restructure the business around data ownership, streamlining operations and increasing profitability. The result? A six-figure exit within eight months [15].
"In under 8 months, we took Social Link from overwhelmed and inefficient to a 6-figure exit by optimizing operations, increasing profitability, and positioning them as an acquisition-ready business." - Danny P, CEO of Social Link [15]
The key to Social Link’s success wasn’t a groundbreaking product or a proprietary algorithm. It was their ability to present clean, organized, and proprietary data that highlighted operational efficiency and predictable growth. Buyers weren’t just purchasing a product; they were acquiring a well-structured data asset that could seamlessly integrate into their own systems. This demonstrates the power of data ownership in driving higher exit multiples.
These examples highlight how companies can package financials, operational procedures, and growth metrics into a compelling narrative for buyers. In today’s market, where 80% of strategic and private equity buyers report higher valuations for companies with deeply integrated AI and data systems [16], this approach can mean the difference between an average exit and a premium one.
How Founders Can Succeed in the Data Era
The move from growth-focused strategies to data-driven models requires more than just a mindset shift - it demands real operational changes. Founders who understand this are rethinking their entire approach, prioritizing data ownership over simple data collection. Here's how you can make that leap.
Review and Improve Your Data Assets
Start by auditing your data. Ask yourself: Do you truly own your data, or are you just borrowing it? Mohammed Shehu Ahmed, Agentic AI Systems Architect, puts it bluntly:
"If you cannot run a SQL query against your customer list right now, you do not own it." [6]
Many founders overestimate their control over data when they rely on platform exports. Data from CSV files, for instance, has limited utility in driving meaningful insights [6].
Think of your data assets as a hierarchy. At the bottom is basic data - server logs and telemetry. While easy to gather, it offers minimal competitive advantage. One step up is operational data, like transactions and workflows, which holds slightly more value. Interactional data, such as user behaviors and preferences, is where things get interesting - it reflects how users truly engage with your system. At the top is learning data - feedback, corrections, and reinforcement signals - data that actively improves your system and is hard for competitors to replicate [13].
To assess your position, consider this: Which data actively enhances your system's decision-making? As Alex Pawlowski of The Strategy Stack explains:
"Data is no longer scarce. Signal is." [13]
Instead of passively collecting logs, focus on capturing meaningful patterns, like user interactions and corrections. Once you've identified these opportunities, build agile data pipelines to turn raw data into actionable insights quickly.
Set Up AI-Powered Data Pipelines
Your proprietary data is your edge. But it’s not just about collecting it - it’s about designing systems that make the most of it. For this, your data pipelines need to be dynamic, continuously improving their performance [13][14].
A two-tiered system works best. Short loops handle real-time feedback, allowing AI systems to adjust actions immediately. Long loops focus on periodic model training and fine-tuning, which typically occurs weekly or monthly [14]. Companies that update their systems weekly gain intelligence much faster than those that only revisit their models quarterly [13].
To maximize control, move away from third-party SaaS tools. Use solutions like Airbyte or n8n to extract data from platforms like Salesforce every 15 minutes and store it in a self-hosted database like PostgreSQL [6]. The cost difference can be staggering: maintaining 10 million rows of customer data on a private VPS might only cost $20 per month, while relying on Salesforce could rack up overage fees of $50,000 annually [6]. Beyond cost, companies with direct control over their data often achieve valuation multiples of 8×–12× EBITDA, compared to just 3×–5× for those dependent on rented SaaS data [6].
Once your pipelines are operational, integrate them into a business framework that prioritizes direct data ownership.
Structure Your Business Around Data Ownership
Data ownership isn’t just a technical issue - it’s a core business strategy. Your agreements and operations should ensure you can directly query and manipulate your operational data without relying on third parties [6]. This setup not only streamlines operations but also significantly boosts your company’s valuation.
Create a Golden Data Layer - a unified, governed source of truth that defines your key business entities and metrics [5]. This layer ensures consistency across your organization, prevents fragmented data outputs, and reassures potential investors or buyers that your data is clean, organized, and proprietary.
Looking ahead, the real challenge isn’t about amassing more data. As Alex Pawlowski notes:
"The strategic question in 2026 is no longer how much data you have. It is what your system is able to learn from that data - and how quickly." [13]
To stay ahead, design your product to capture user corrections and increase the frequency of data loops. Frequent events, like code edits, create competitive advantages far faster than sporadic ones, such as annual reports [14]. The winners in this era won’t just collect data - they’ll build systems that learn and improve with every interaction.
Tools for Building Data Advantages in SaaS and AI
The right tools can turn scattered data into a powerful competitive edge. But not all platforms allow for true data ownership. The best solutions go beyond traditional business intelligence, offering features like autonomous intelligence, local processing, and cross-system auditing. Here are some standout platforms redefining the game.
Start with tools that unify fragmented data. Oraion connects over 700 sources into a single source of truth, allowing teams to query data in plain English instead of SQL. This shift empowers businesses with direct, actionable insights. Stephen Flood, CEO of GoldCore, captures its impact:
"It's like having a supercharged data analyst who never sleeps. What once took weeks is now completed in a couple of hours." [17]
Oraion users report saving over 9,000 hours annually and cutting analysis turnaround time by 70% [17]. For industries requiring strict compliance, Atlas Analytics processes data locally, ensuring adherence to HIPAA and GDPR while reducing cloud infrastructure costs. Its edge-native processing uses 70-billion parameter models on local hardware, with pricing starting at $199 per month [20].
Parse stands out with autonomous auditing. It scans systems like Stripe, HubSpot, Jira, and GitHub to uncover issues that traditional dashboards might miss. By analyzing over 1.5 billion signals monthly, Parse reduces decision lead times by 25% [18].
For revenue optimization, Atlas links real-time usage data directly to billing systems. Shikhar Mistra, Founder of EGI, describes it as "Google Tag Manager meets Stripe", enabling quick pricing adjustments [19].
Omni Analytics focuses on consistent and governed AI insights through its semantic layer. Priya Gupta, Head of Data at Cribl, explains:
"Our big lesson with AI is that it's about control. When you constrain it and give it context, like Omni's semantic layer does, you get predictable, reliable results that drive action." [21]
Data-Focused Tools Comparison
| Tool Name | Key Data Feature | Impact on Exit Multiple | SaaS Pricing Fit |
|---|---|---|---|
| Oraion | 700+ integrations & Context Catalog | Creates a "Single Source of Truth"; 70% faster analysis [17] | Scale-ups to Enterprise |
| Parse | Autonomous cross-system auditing | Identifies revenue leakage and "Commercial Truth" [18] | $1,200 - $4,000/mo |
| Atlas | Pricing Iteration Engine & Super SDK | Optimizes LTV and expansion revenue via billing control [19] | AI & PLG Startups |
| Atlas Analytics | Edge-native local processing | Eliminates cloud costs; ensures high-level compliance [20] | $199 - $999/mo |
| Omni Analytics | Semantic Model & Workbook UI | Enables self-service; reduces ad-hoc data team burden [21] | Mid-market to Enterprise |
These tools showcase how AI-native platforms simplify decision-making compared to traditional setups. Conventional business intelligence systems often require hefty investments - around $175,000 to $250,000 annually - and take weeks to deploy [18]. In contrast, platforms like Oraion and Parse can be operational for $1,000 to $5,000 per month [18]. Plus, they uncover insights that static dashboards might miss, such as a critical GitHub commit delaying EU payments or enterprise deals stalled by missing features [18].
The takeaway is clear: owning and leveraging data effectively is essential for increasing exit multiples. Platforms that improve data ownership and streamline decisions not only address hidden operational issues but also strengthen market positioning.
Conclusion: Data-Driven Founders Will Win
The game has shifted. The "growth at all costs" mindset thrived in a time of low capital and slim margins, but that era is long gone. By 2026, investors are prioritizing gross profit growth and placing a premium on data ownership rather than sheer user numbers. Companies with proprietary data now enjoy much higher valuation multiples.
This shift became painfully clear during the February 2026 "SaaSpocalypse", when over $1 trillion in SaaS value evaporated as AI transformed traditional workflows into commodities. Public SaaS valuation multiples plummeted from 18–21x in 2021 to just 5–7x today. On top of that, 35% of companies have replaced at least one SaaS tool with a custom-built AI alternative [3]. The old competitive edges, like proprietary code, no longer hold up. Now, exclusive data is the ultimate advantage.
"In the age of AI, data is not just an asset; it's the ultimate moat." - Sriram Parthasarathy [1]
This new reality leaves founders with a clear directive: audit your data assets, secure ownership, and build systems that ensure sovereignty over your data. Businesses must now focus on gross profit margins and Net Revenue Retention rather than chasing top-line growth. Modern automation tools and data integration platforms make it easier to consolidate scattered data, generate insights faster, and take action based on those insights. These strategies align perfectly with the market priorities we've seen emerge.
The choice is stark: control your data or risk losing your competitive edge. Companies that build data flywheels and proprietary "golden layers" will command higher valuations. On the other hand, those clinging to outdated growth-at-all-costs strategies may find themselves stuck in a downward spiral. The age of data-driven defensibility is here - and it’s not going anywhere.
FAQs
What counts as “owned” data versus “rented” data?
"Owned" data refers to information that a company fully controls. This data is stored in systems the company manages directly, such as proprietary or self-hosted platforms, giving them exclusive rights and unrestricted access.
In contrast, "rented" data is housed on third-party SaaS platforms. While companies can access this data, their control is often limited, and there may be restrictions or additional costs when attempting to extract or transfer it.
How can I build a data flywheel in my SaaS product?
To create a data flywheel, you’ll need a feedback loop that continuously gathers, processes, and applies user data to refine your product and fuel growth. Start by collecting exclusive user data that only your product can provide. Then, analyze this data to uncover actionable insights. Use these insights to improve your product’s features and refine AI models. Over time, this cycle of constant improvement increases your product’s value and builds a strong competitive edge, often referred to as a "data moat."
What should I do first to become “data sovereign”?
To achieve "data sovereignty", begin by shifting away from external SaaS platforms and establishing your own data infrastructure. This involves migrating your data from proprietary silos to open, self-hosted databases like Postgres, giving you complete control over your information. True data sovereignty is about emphasizing ownership and custody of your data, reducing dependence on third-party vendors, and setting up systems that enable you to operate independently with your data assets.